让小龙虾发挥最大效果的模型组合策略(附我的真实配置)
让小龙虾发挥最大效果的模型组合策略(附我的真实配置)
用 OpenClaw 的人,基本都会碰到两个问题。
一个是 Token 焦虑。用着用着触发限额,报错 API Rate Limit,任务直接中断。感觉钱没少花,但总在不该断的地方断。
另一个是选模型选到头大。Claude、GPT、Kimi、GLM、MiniMax……每家都说自己最强,每家都在推套餐,你根本不知道该订哪个,或者干脆全订了,结果发现大部分时间根本用不到。
这两个问题,其实是同一个问题:没有用对模型组合策略。
今天这篇,我把怎么选模型、怎么组合、怎么配置、怎么切换,完整说一遍。最后会把我自己真实在用的四层配置方案全部公开。
一、模型评测:到底哪个最好?
选模型之前,先要有靠谱的数据参考,不能靠感觉。
我推荐大家看 Pinchbench,这个网站专门评测各个模型跑小龙虾的表现,覆盖指令遵循、代码、写作等核心维度,数据持续更新。跟网上那些一次性评测文章不同,它的数据会随着模型版本迭代同步更新。
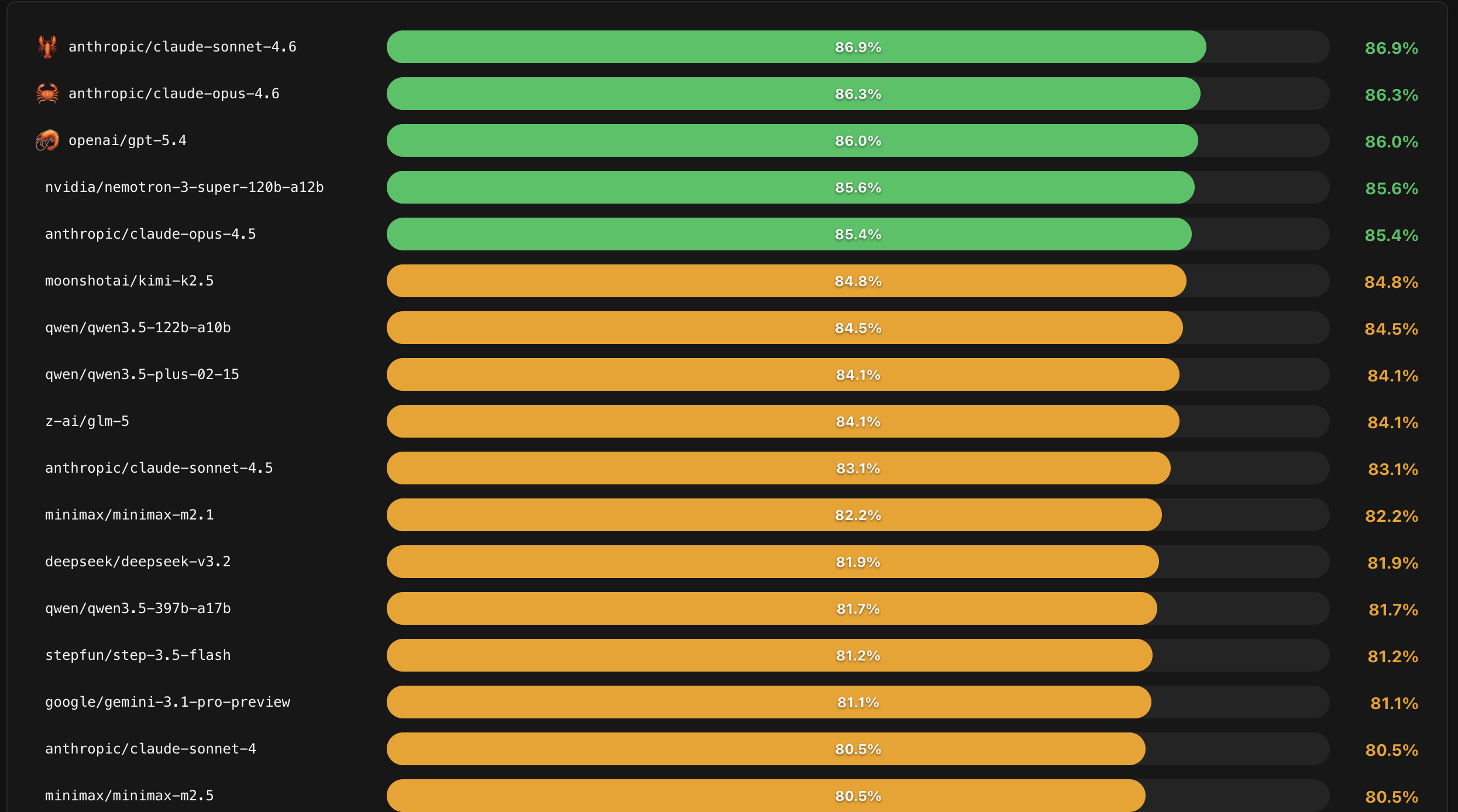 图01: PinchBench评测数据
图01: PinchBench评测数据
我根据 Pinchbench 的评测数据,结合我自己实际使用的真实体感,先给大家一个明确的结论:
顶级模型,首选 Claude。
Claude 的 Opus 4.6 和 Sonnet 4.6,目前综合表现没有对手。Claude价格最贵,同样价格的套餐,Token也最少,但它确实就是最好用的。
Claude 有个特点:人狠话不多。你给它指令,它不会跟你废话,直接执行,而且方向不会跑偏。这对小龙虾这种"要大量交互、要理解复杂指令"的使用场景,非常关键。
GPT-5.4 和 GPT-5.3 Codex 紧随其后。
GPT 的毛病是非常啰嗦,回一件事能绕半天,但结果通常是对的。和Claude有一定差距,但是差距并不大。
性价比角度,GPT Plus 20 美元订阅值得——里面包含的 Codex 模型 Token 额度相当大,日常任务完全够用。
至于Google的 Gemini 3.1,直接放弃。
评测数据靠后,甚至不如国产模型。我自己使用下来的体感,Gemini 的指令遵循能力差,经常跑偏。
当然,你肯定很感兴趣:国产模型到底哪个最好? 我直接给答案:
月之暗面的 Kimi K2.5 是目前最强的国产选择,评分仅次于 Claude 和 GPT,算是国产模型中跑小龙虾的最佳选择。
其次是智谱的 GLM-5,评分比 Kimi K2.5 差距不大,效果也相当不错。
而 MiniMax 和 DeepSeek 都相对靠后,和前面的模型有一些差距。
值得一提的是:MiniMax的卖点是又快又便宜,它现在特别受欢迎,很适合用来跑要求不高,但是特别消耗 Token 的任务。
最后,我们来看一类特殊的情况,就是在本地跑大模型,哪个最好呢?
最强的本地开源大模型 就是 Qwen 3.5 122B 的 MoE 模型,推理会激活 10B 参数量。 它的综合能力甚至超过了智谱的 GLM-5,堪称本地大模型最佳选择。只可惜,我的 Mac Studio 只有128GB内存,跑这个122B的模型,实在有些勉强。
目前我实际本地运行的模型是 Qwen3-Coder-Next 80B。这是800 亿参数的 MOE 模型,推理会激活 3B 参数量。 效果也还不错,速度和调用云端模型差不多。
总之,一句话总结: Claude 最强,GPT 次之,国产模型首选 Kimi,本地看内存选 Qwen。
二、模型组合策略:一个主力 + 一个苦力
跑小龙虾,最常见的错误就是用一个模型从头到尾包打天下。要么贵到烧不起,要么省到用着难受。
正确的思路其实很简单:关键场景用最好的模型,普通场景用高性价比的模型。
所以,我们最基础的配置只需要两个模型:
一个是高价值的关键任务模型,负责需要智能、需要推理、需要判断的任务。
另一个是量大管饱的辅助模型,专门接低价值但消耗大的任务——比如网页抓取、文本整理、格式转换这类活儿,用顶级模型来跑纯属浪费。
我推荐的入门组合:GPT-5.4 + Kimi K2.5。
GPT Plus 订阅套餐,每月 20 美元,加上 Kimi 49元人民币的套餐。
这两个加起来一个月不到 200 元人民币,日常使用的小龙虾完全够用了,而且效果非常好。并且这两个都是套餐制,根本不用担心 Token 焦虑。
主控用 GPT-5.4,跑关键任务。辅助用 Kimi K2.5,专门负责那些很消耗 Token 但不需要高智能的任务,比如网页抓取和大量文本分析。
当然,如果你跟我一样忍受不了 GPT-5.4 的啰嗦,也可以用 GPT-5.3 Codex 做主控——废话少,上来直接干活。我自己就是这么选的,下面会详细说。
三、我的真实配置:四层方案全公开
说完了基础组合,你肯定想知道:范老师你自己到底怎么用的?
好,我直接公开。
核心逻辑跟上面说的策略是一样的:越贵的模型越用在刀刃上,越便宜的模型越用来跑低端任务,本地模型作为最后兜底。
我的配置分四层:
第一层:Claude Pro,$20/月 第二层:GPT Plus,$20/月 第三层:Kimi K2.5,49元/月 第四层:本地 Mac Studio 跑 Qwen3-Coder-Next
分配逻辑如下:
主控模型用 GPT-5.3 Codex。
小龙虾的作者官方推荐用 GPT-5.4 配 Medium 推理,我试过,能力确实强,规划很有洞察力。但它实在太啰嗦了,我忍受不了,所以退而求其次用了 GPT-5.3 Codex。Codex 废话少,上来直接干活,主控用这个顺手很多。
高价值任务切 Claude。
碰到关键的任务规划、写作,或者对指令遵循要求很严格的情况,我会切到 Claude,用 Opus 或 Sonnet 来执行。但 Claude Pro 的套餐真的不经用——我用半个多小时就会触发 5 小时限额。所以 Claude 只用在真正值得用的地方,其他时间让 GPT 顶着。
简单高消耗任务交给 Kimi。
大量文档处理、新闻整合、网页爬取这类任务,不需要高智能,但特别消耗 Token,这种活全丢给 Kimi K2.5,完全够用。我在 Claude Code 里也配了 Kimi,处理一些重活。
本地模型作为最后防线。
万一 Claude 和 GPT 的套餐都触顶了,Kimi 替补主控,本地模型补位 Kimi 原本的角色。万一 Kimi 也用完了,全切本地模型。这四层互相兜底,不会有哪个环节断掉。
算下来每月花多少?
GPT Plus 20美元, Claude Pro 20美元。Kimi 49元人民币,一个月费用不到 330 元。如果编程任务重,Claude Code 消耗 Kimi 多,我最多把 Kimi 升到 99 元套餐,这样一个月下来,也不到 380 元人民币。
足够我覆盖所有 AI 使用需求了,封顶380元人民币。效果非常的赞。
四、配置实操:怎么把这套方案落地
方案定了,怎么在小龙虾里配起来?分三步。
实操分三步:配置模型套餐、定义使用策略、日常怎么切换。
第一步:配置模型套餐到 OpenClaw
打开终端控制台,执行 openclaw configure 命令,启动后就可以在 model 选项里配置你想要的模型。
我推荐配置这几家:
• OpenAI(GPT 系列) • Anthropic(Claude 系列)—— 高价值模型 • 月之暗面的 Kimi K2.5 —— 国产首选 • 也可以配 MiniMax 或智谱 GLM
如何配置模型,我之前做过两个视频,专门讲怎么配置:
- 《OpenClaw 从零到可用》
- 《OpenClaw 订阅套餐的打开方式》
大家可以直接去看那两期,不重复讲了。
第二步:用 AI 工具修改配置文件
假设你已经配好了 GPT、Kimi 和本地 Qwen 三个套餐,接下来要告诉 OpenClaw 怎么用它们。
需要定义两件事:
第一,主控模型是什么。我用的是 GPT-5.3 Codex。
第二,当主控触发限额时,兜底模型是谁。我配的是 Kimi K2.5。
除了主会话,OpenClaw 在执行重度任务时会启动一个子代理(subagent)去跑。subagent 是干重活的,不应该用主控模型烧额度,所以 subagent 的默认模型我配的也是 Kimi K2.5。如果 Kimi 也触发了限额,subagent 的兜底就是本地 Qwen 模型。
整理成一套策略就是:
- 主控:GPT-5.3 Codex
- 主控兜底:Kimi K2.5
- Subagent:Kimi K2.5
- Subagent 兜底:本地 Qwen
这套策略要写进 openclaw.json 配置文件。
手工改 JSON 很容易出错,改错了 OpenClaw 重启起不来,整个小龙虾就挂了。我的做法是:让另一个 AI 工具来改这个文件。
 图02: 用VSCode插件Codex修改openclaw.json
图02: 用VSCode插件Codex修改openclaw.json
以我为例,打开 VS Code 里的 Codex 插件,加载 ~/.openclaw/openclaw.json 配置文件,然后用自然语言告诉它我的策略,让 Codex 帮我修改配置文件,改完让它顺手检测一下配置是否正确,再让它帮我重启 OpenClaw Gateway。所有模型就全部生效了。
我现在展示的这些配置,都是让 Codex 帮我改的,我自己不动手。
第三步:日常使用怎么切换
小龙虾目前不支持按任务类型自动切模型,需要我们自己手工通过斜杠命令切换。给大家演示一下:
默认主控模型,我用 GPT 5.3 或 5.4 都可以。输入 /model gpt-5.4,然后输入 /status,可以看到当前模型已经切到 GPT 5.4 了。
如果要做高价值任务,比如深度写作,就切到 Claude Opus:/model opus。
如果要做消耗大但价值低的任务,比如文档处理,就切到 Kimi:/model kimi。
如果想跑本地模型,就切到千问:/model qwen。
就是通过斜杠命令手工切换,根据不同场景选用不同模型。
触发限额时,OpenClaw 会自动 Failover 切到你配置的兜底模型,不需要手动干预。