
让小龙虾发挥最大效果的模型组合策略(附我的真实配置)


用 OpenClaw 的人,基本都会碰到两个问题。
一个是 Token 焦虑。用着用着触发限额,报错 API Rate Limit,任务直接中断。感觉钱没少花,但总在不该断的地方断。
另一个是选模型选到头大。Claude、GPT、Kimi、GLM、MiniMax……每家都说自己最强,每家都在推套餐,你根本不知道该订哪个,或者干脆全订了,结果发现大部分时间根本用不到。
这两个问题,其实是同一个问题:没有用对模型组合策略。
今天这篇,我把怎么选模型、怎么组合、怎么配置、怎么切换,完整说一遍。最后会把我自己真实在用的四层配置方案全部公开。
一、模型评测:到底哪个最好?
选模型之前,先要有靠谱的数据参考,不能靠感觉。
我推荐大家看 Pinchbench,这个网站专门评测各个模型跑小龙虾的表现,覆盖指令遵循、代码、写作等核心维度,数据持续更新。跟网上那些一次性评测文章不同,它的数据会随着模型版本迭代同步更新。
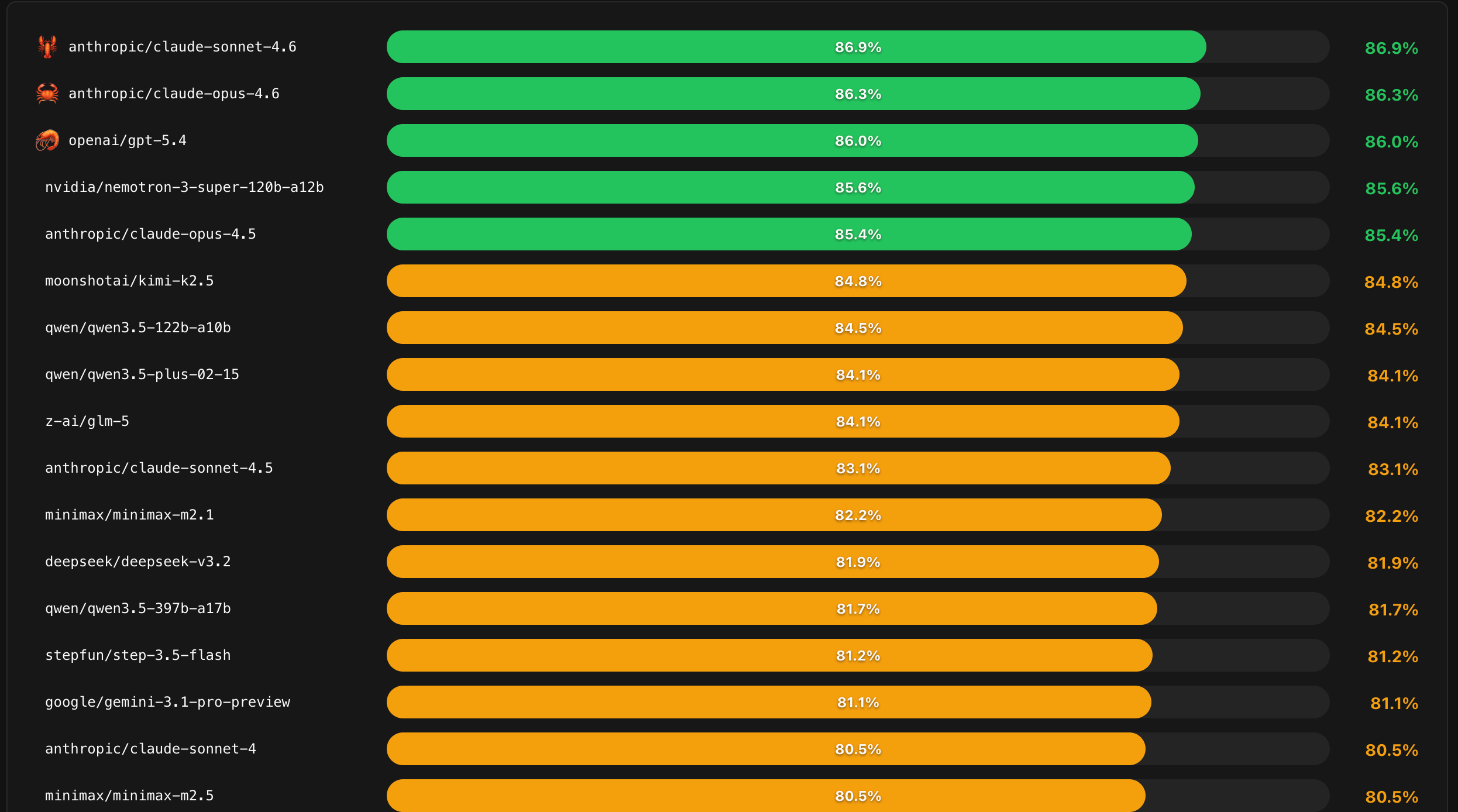
图01: PinchBench评测数据
我根据 Pitchbench 的评测数据,结合我自己实际使用的真实体感,先给大家一个明确的结论:
顶级模型,首选 Claude。
Claude 的 Opus 4.6 和 Sonnet 4.6,目前综合表现没有对手。Claude价格最贵,同样价格的套餐,Token也最少,但它确实就是最好用的。
Claude 有个特点:人狠话不多。你给它指令,它不会跟你废话,直接执行,而且方向不会跑偏。这对小龙虾这种”要大量交互、要理解复杂指令”的使用场景,非常关键。
GPT-5.4 和 GPT-5.3 Codex 紧随其后。
GPT 的毛病是非常啰嗦,回一件事能绕半天,但结果通常是对的。和Claude有一定差距,但是差距并不大。
性价比角度,GPT Plus 20 美元订阅值得——里面包含的 Codex 模型 Token 额度相当大,日常任务完全够用。
至于Google的 Gemini 3.1,我劝你直接放弃。
评测数据靠后,甚至不如国产模型。我自己使用下来的体感,Gemini 的指令遵循能力差,经常跑偏。
当然,你肯定很感兴趣:国产模型到底哪个最好? 我直接给答案:
月之暗面的 Kimi K2.5 是目前最强的国产选择,评分仅次于 Claude 和 GPT,算是国产模型中跑小龙虾的最佳选择。
其次是智谱的 GLM-5,评分比 Kimi K2.5 差距不大,效果也相当不错。
而 MiniMax 和 DeepSeek 都相对靠后,和前面的模型有一些差距。
值得一提的是:MiniMax的卖点是又快又便宜,它现在特别受欢迎,很适合用来跑要求不高,但是特别消耗 Token 的任务。
最后,我们来看一类特殊的情况,就是在本地跑大模型,哪个最好呢?
最强的本地开源大模型 就是 Qwen 3.5 122B 的 MoE 模型,推理会激活 10B 参数量。 它的综合能力甚至超过了智谱的 GLM-5,堪称本地大模型最佳选择。只可惜,我的 Mac Studio 只有128GB内存,跑这个122B的模型,实在有些勉强。
目前我实际本地运行的模型是 Qwen3-Coder-Next 80B。这是800 亿参数的 MOE 模型,推理会激活 3B 参数量。 效果也还不错,速度和调用云端模型差不多。
总之,一句话总结: Claude 最强,GPT 次之,国产模型首选 Kimi,本地看内存选 Qwen。
二、模型组合策略:一个主力 + 一个苦力
跑小龙虾,最常见的错误就是用一个模型从头到尾包打天下。要么贵到烧不起,要么省到用着难受。
正确的思路其实很简单:关键场景用最好的模型,普通场景用高性价比的模型。
所以,我们最基础的配置只需要两个模型:
一个是高价值的关键任务模型,负责需要智能、需要推理、需要判断的任务。
另一个是量大管饱的辅助模型,专门接低价值但消耗大的任务——比如网页抓取、文本整理、格式转换这类活儿,用顶级模型来跑纯属浪费。
我推荐的入门组合:GPT-5.4 + Kimi K2.5。
GPT Plus 订阅套餐,每月 20 美元,加上 Kimi 49元人民币的套餐。
这两个加起来一个月不到 200 元人民币,日常使用的小龙虾完全够用了,而且效果非常好。并且这两个都是套餐制,根本不用担心 Token 焦虑。
主控用 GPT-5.4,跑关键任务。辅助用 Kimi K2.5,专门负责那些很消耗 Token 但不需要高智能的任务,比如网页抓取和大量文本分析。
当然,如果你跟我一样忍受不了 GPT-5.4 的啰嗦,也可以用 GPT-5.3 Codex 做主控——废话少,上来直接干活。我自己就是这么选的,下面会详细说。
三、我的真实配置:四层方案全公开
说完了基础组合,你肯定想知道:范老师你自己到底怎么用的?
好,我直接公开。
